Big Data, Small Data, and Everything In Between
Who Am I? What Am I Doing Here?
| Catallaxy Services |  @feaselkl |
|
 |
Curated SQL | |
 |
We Speak Linux |
What Are We Talking About Here?
As data size expands, numerous products have entered the data storage market to solve particular pain points. This talk will cover, at a high level, many of the data storage technologies currently available on the market.
Motivation
The expansion of data sets and increased expectations of businesses for analysis and modeling of data has led developers to create a number of database products to meet those needs. As data professionals, it is incumbent upon us to understand how these tools work and put them to their best use--before somebody else puts them to sub-optimal use.
Definitions: Big Data
When you have too much data to fit into Excel.
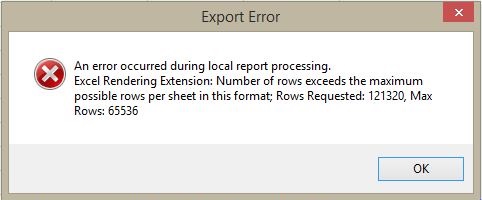
Definitions: Big Data
Big Data is built around four major dimensions:
- Volume - sheer quantity of data
- Variety - data in different formats, different media types, and different structures interacting
- Velocity - number of data points collected over time
- Veracity - accuracy of data
Definitions: Small Data
- Data sets small enough for human comprehension.
- Data sets small enough to fit into a single machine's memory (e.g., R or Redis data)
Definitions: Medium Data
Data sets too large to fit on a single machine but not large enough to require a massive cluster.
SparkR (R but able to use a Spark cluster's memory) is a good example of a product which thrives in the Medium Data space.
Architecture Overview

Architecture Overview
Stress Points:
- Response time (especially global)
- Ease of use for reporting and analysis
- Cost of scaling up hardware
- Semi-structured or unstructured data
- Extreme write load
Architecture Overview

Architecture Overview
For each technology, we will:
- Give a quick explanation of the technology
- Give a quick overview of popular products in the field
- Discuss the pros and cons of this technology
- Describe some of the best uses for this technology
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Relational Database
Quick Explanation
Relational databases are built off of set theory, a branch of mathematics dedicated to dealing with collections of things.

Relational Database
Key Players
Commercial



Open Source


Relational Database
Product Advantages
- ACID compliant
- Pessimistic or optimistic concurrency available
- Fully-featured DSLs (T-SQL, PL/SQL, etc.)
- Excellent tooling
- Great community support
- Huge institutional acceptance
Relational Database
Product Drawbacks
- S-shaped learning curve
- Scaling model is typically "Up" rather than "Out"
- Commercial products are expensive
Relational Database
Best Uses
- Backbone of a business application
- Financial applications which require conistency
- "You're fired if this is wrong" data
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Multidimensional DB
Quick Explanation
Multidimensional databases are used for reporting and business analysis and are made up of several parts.

Enterprise Data Warehouse
Key Players


Enterprise Data Warehouse
Product Advantages
- Single view of cross-organization data for reporting
- Central location for important, known business questions
- Great tooling support
- Easier for non-IT staff to query
- Moves reporting queries off of busy transactional systems
Enterprise Data Warehouse
Product Drawbacks
- Extremely long development cycle
- Requires full company committment
- High risk of failure
- Huge data sizes can lead to slow queries
Enterprise Data Warehouse
Best Uses
- Answering known business questions
- Getting a single view of data for analytics
- Data mining
OLAP Cube
Key Players

OLAP Cube
Product Advantages
- Pre-aggregated measures make queries much faster
- Tight integration into Excel and other reporting tools
- Powerful DSLs (MDX) make cube querying easier
OLAP Cube
Product Drawbacks
- Extremely long development cycle
- Requires full company committment
- High risk of failure
- Data usually not real-time
OLAP Cube
Best Uses
- Data mining
- Excel-based reporting
- Business analyst research
Data Mart
Key Players
Data Mart
Product Advantages
- Divisional focus
- Hybrid of EDW data and OLTP design
- Flexible model: DM --> EDW, EDW --> DM, or just DM
Data Mart
Product Drawbacks
- Extremely long development cycle
- Normalized data structure not as intuitive for analysts
Data Mart
Best Uses
- Fast departmental reporting
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Hadoop
Quick Explanation
Hadoop is a massive, distributed, batch processing system.

Hadoop
Key Players



Hadoop
Product Advantages
- Built to run on cheap hardware
- Linear scale
- Large, active community
- Plenty of tools and add-ons

Hadoop
Product Drawbacks
- Map-Reduce is SLOW
- Map-Reduce takes a lot of code
- Primitive IDEs
- Consistency not guaranteed
Hadoop
Best Uses
- Batch analytics on massive data sets
- Semi-structured, text-heavy data sets
- Key component in the Data Lake model
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Columnstore Database
Quick Explanation
A columnstore table stores sections of columnar data rather than rows of data.


Columnstore Database
Key Players




Columnstore Database
Product Advantages
- Very fast insertion (HBase, BigTable, Cassandra)
- Possibility for great data compression (SQL Server, Exadata)
- Great for complex ETL operations
- Relational columnstore ACID-compliant
Columnstore Database
Product Drawbacks
- Less efficient as more columns needed
- Non-relational columnstore forbids joins
- Querying against non-keys impossible in some (HBase)
- Non-relational columnstore not guaranteed consistent
Columnstore Database
Best Uses
Relational
- Warehouse fact tables
- Aggregation over lots of rows but not many columns
Non-Relational
- Search engines
- Massive scale writes
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
In-Memory Cache
Quick Explanation
Key-value pairs stored in memory on a RAM-heavy cache server. CPU count is not necessarily important for this server, but RAM is.

In-Memory Cache
Key Players





In-Memory Cache
Product Advantages
- Single-threaded cache easy to develop against
- Extremely fast
- Very easy to hook into a system
In-Memory Cache
Product Drawbacks
- Single-threaded cache can get overwhelmed
- Tooling is generally lacking
In-Memory Cache
Best Uses
- Cache lookup data in front of an OLTP system
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Key-Value Database
Quick Explanation
Data stored as key-value pairs. This data may be modelled with more complex data types.

Key-Value Database
Key Players


Key-Value Database
Product Advantages
- Table design akin to relational table
- Conflict-free Replicated Data Types available to maintain consistency (Riak)
- Able to support high write volume
Key-Value Database
Product Drawbacks
- Typically no joins allowed
- Middle-ground table design gets muddy
- Chokes with larger record sizes (~1-5MB)
- Most Key-Value databases don't support CRDTs
Key-Value Database
Best Uses
- Shopping carts (Dynamo designed for this)
- Product listings
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Document Database
Quick Explanation
Document databases are sub-sets of Key-Value databases where the value is an element with an internal structure (e.g., JSON or XML). This is designed for nesting and holding an entire object's structure in one record.

Document Database
Key Players



Document Database
Product Advantages
- Fast retrieval of individual records
- One call per object
- Records can have different internal structures
- Some products can index values for searches (e.g., MongoDB)
Document Database
Product Drawbacks
- Eventual consistency (isn't)
- Typically no joins
Document Database
Best Uses
- Product listing cache
- Main storage for less-valuable data (e.g., company directory, comments section)
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Graph Database
Quick Explanation
Graph databases store associative data as edges and nodes, where edges are first-class citizens.

Graph Database
Key Players


Graph Database
Product Advantages
- Track associations between elements using edges
- Weigh edges and perform calculations
- In SQL Server 2017, graphs are stored as relations
Graph Database
Product Drawbacks
- Weak tooling
- Aggregation functions are difficult
- Language requires two concepts to represent information
- Graphs assume specific data access patterns
- In SQL Server 2017, graphs are stored as relations
Graph Database
Best Uses
- Network mapping
- Solving traversal problems (e.g., traveling salesman problem)
- Solving transitivity problems (e.g., recommenders)
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Full-Text Search
Quick Explanation
Distributed database used for text searches.

Full-Text Search
Key Players

![]()



Full-Text Search
Product Advantages
- Extremely fast text search
- Could be primary analysis store for logs
Full-Text Search
Product Drawbacks
- Should not be the primary data store for much
- Limited aggregation options
Full-Text Search
Best Uses
- Text search / Search engine
- Web crawlers (Nutch)
- Log storage (Elasticsearch + Logstash; Splunk)
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Message Queue
Quick Explanation
A publisher/subscriber system with storage of messages in a queue. Messages may get removed after processing (e.g., MSMQ, Service Broker), or they may drop off the queue after a certain amount of time (e.g., Kafka, Kinesis).

Message Queue
Key Players


- Microsoft Message Queue (MSMQ)
- Service Broker
Message Queue
Product Advantages
- Well-established pattern
- Several high-quality products available
Message Queue
Product Drawbacks
- Poison pill messages can take down queue
- Not trivial to scale to high load
- Some level of "magic" when debugging
Message Queue
Best Uses
- Linking data systems together
- Passing messages between systems
- Service-Oriented Architecture (SOA)
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Stream Processing
Quick Explanation
A distributed real-time computation system. Integrates with a message queue and performs some set of actions with the data, like calculating aggregations or cleansing data.

Message Queue
Key Players



Stream Processing
Product Advantages
- Real-time processing
- Offers ability for data cleansing
- Can use to build aggregates and analyze individual messages
- Can trigger real-time actions from statistical data
Stream Processing
Product Drawbacks
- Most tools Java-based (ick!)
- Lots of hand-coding Java
- Limited tooling available
Stream Processing
Best Uses
- Real-time analytics
- Digesting messages and sending results to different data stores
Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
World of Azure
Quick Explanation
Most of the tools discussed here have Microsoft Azure Platform-as-a-Service or Software-as-a-Service versions available. We discussed some of them in earlier slides, but this section will cover Azure versions of all of the tools.
World of Azure
Software Available
- OLTP system - Azure SQL Database
- EDW - Azure SQL Data Warehouse
- Cube - Azure Analysis Services (Tabular only!)
- Data Marts - Azure SQL Database
- Hadoop Cluster - HDInsight
- Columnstore Database - HBase on HDInsight, Columnstore indexes on Azure SQL Database or Azure SQL Data Warehouse
World of Azure
Software Available
- In-Memory Cache - Azure Redis
- Document Database - DocumentDB
- Key-Value Database - Azure table storage; can also install Riak, Cassandra, etc. on Azure using templates
- Graph Database - SQL 2017 -- Azure coming?
- Full-Text Engine - Azure Search
- Message Queue - Azure Event Hub
- Stream Processing - Stream Analytics
World of Azure
Data Lake
Microsoft is pushing the concept of a data lake: a collection of different data stores in different formats accessable through a common language (U-SQL).

Technologies
- Relational Database
- Multidimensional Database
- Hadoop Cluster
- Columnstore Database
- In-Memory Cache
- Key-Value Database
- Document Database
- Graph Database
- Full-Text Search Engine
- Message Queue System
- Stream Processing System
- World of Azure
- Consumers
Consumers
Quick Explanation
We all know about web applications, thick clients, and tools like Excel. Here are a couple interesting subsets of tools which help understand and visualize the data we're storing.
Analytics Tools
Key Players



Analytics Tools
Best Uses
- Data cleansing
- Predictive modeling
- Statistical analysis
- Rough draft graphing
Visualization Tools
Key Players



Visualization Tools
Best Uses
- Graphing, charting, and visualizing data
- Dashboards
- Building reports for end users (and letting end users build their own reports)
- Final draft visualizations
Wrapping Up
There is a plethora of data storage methods available to you. Choose the one(s) best-suited for your organization and data needs.
To learn more, go here: http://CSmore.info/on/bigdata
And for help, contact me: feasel@catallaxyservices.com | @feaselkl