Getting Started with Apache Spark
Kevin Feasel (@feaselkl)https://csmore.info/on/spark
Who Am I? What Am I Doing Here?



Agenda
- The Origins of Spark
- Installing Spark
- Functional Spark
- Our First Examples
- Spark SQL
- Databricks UAP
- .NET for Apache Spark
The Origins of Hadoop
Hadoop started as a pair of Google whitepapers: the Google File System (released in 2003) and MapReduce (2004). Doug Cutting, while working at Yahoo, applied these concepts to search engine processing. The first public release of Hadoop was in early 2006.
Since then, Hadoop has taken off as its own ecosystem, allowing companies to process petabytes of data efficiently over thousands of machines.
Great Use Cases for Hadoop
- Processing gigantic numbers of records, where a single-server solution is cost prohibitive or unavailable.
- "Cold storage" of relational data, especially using Polybase.
- Real-time ETL and streaming of data.
- Statistical analysis of gigantic data sets.
- A central data repository (data lake), which can feed other sources (like warehouses).
The Birth of Hadoop: 2007-2011
The hardware paradigm during the early years:
- Many servers with direct attached storage.
- Storage was primarily spinning disk.
- Servers were held on-prem.
- Servers were phyiscal machines.
- There was some expectation of server failure.
This hardware paradigm drove technical decisions around data storage, including the Hadoop Distributed Filesystem (HDFS).
The Birth of Hadoop: 2007-2011
The software paradigm during the early years:
- On Linux, C is popular but Java is more portable.
- RAM is much faster than disk but is limited.
- Network bandwidth is somewhat limited.
- Data structure is context-sensitive and the same file may have several structures.
- Developers know the data context when they write their code.
This led to node types, semi-structured data storage, and MapReduce.
Node Types in Hadoop
There are two primary node types in Hadoop: the NameNode and data nodes.
The NameNode (aka control or head node) is responsible for communication with the outside world, coordination with data nodes, and ensuring that jobs run.
Data nodes store data and execute code, making results available to the NameNode.
Data Retrieval in Hadoop
Hadoop follows a "semi-structured" data model: you define the data structure not when adding files to HDFS, but rather upon retrieval. You can still do ETL and data integrity checks before moving data to HDFS, but it is not mandatory.
In contrast, a relational database has a structured data model: queries can make good assumptions about data integrity and structure.
Data Retrieval in Hadoop
Semi-structured data helps when:
- Different lines have different sets of values.
- Even if the lines are the same, different applications need the data aligned different ways.

MapReduce
MapReduce is built around two FP constructs:
- Map: filter and sort data
- Reduce: aggregate data
MapReduce combines map and reduce calls to transform data into desired outputs.
The nodes which perform mapping may not be the same nodes which perform reduction, allowing for large-scale performance improvement.
What Went Right?
- Able to process files too large for a single server
- Solved important problems for enormous companies
- Hadoop built up an amazing ecosystem
- Databases: HBase, Phoenix, Hive, Impala
- Data movers: Pig, Flume, Sqoop
- Streaming: Storm, Kafka, Spark, Flink
What Went Wrong?
- MapReduce can be SLOW – many reads and writes against slow spinning disk.
- Hardware changes over time stretched and sometimes broke Hadoop assumptions:
- Spinning disk DAS >> SSD and SANs >> NVMe
- Much more RAM on a single box (e.g., 2TB)
- Physical hardware >> On-prem VM >> Cloud
Some of these changes precipitated the research project which became Apache Spark.
The Genesis of Spark
Spark started as a research project at the University of California Berkeley’s Algorithms, Machines, People Lab (AMPLab) in 2009. The project's goal was to develop in-memory cluster computing, avoiding MapReduce's reliance on heavy I/O use.
The first open source release of Spark was 2010, concurrent with a paper from Matei Zaharia, et al.
In 2012, Zaharia, et al release a paper on Resilient Distributed Datasets.
Resilient Distributed Datasets
The Resilient Distributed Dataset (RDD) forms the core of Apache Spark. It is:
- Immutable – you never change an RDD itself; instead, you apply transformation functions to return a new RDD
Resilient Distributed Datasets
The Resilient Distributed Dataset (RDD) forms the core of Apache Spark. It is:
- Immutable
- Distributed – executors (akin to data nodes) split up the data set into sizes small enough to fit into those machines’ memory
Resilient Distributed Datasets
The Resilient Distributed Dataset (RDD) forms the core of Apache Spark. It is:
- Immutable
- Distributed
- Resilient – in the event that one executor fails, the driver (akin to a name node) recognizes this failure and enlists a new executor to finish the job
Resilient Distributed Datasets
The Resilient Distributed Dataset (RDD) forms the core of Apache Spark. It is:
- Immutable
- Distributed
- Resilient
- Lazy – Executors try to minimize the number of data-changing operations
Add all of this together and you have the key component behind Spark.
Agenda
- The Origins of Spark
- Installing Spark
- Functional Spark
- Our First Examples
- Spark SQL
- Databricks UAP
- .NET for Apache Spark
Installation Options
We have several options available to install Spark:
- Install stand-alone (Linux, Windows, or Mac)
- Use with a Hadoop distribution like Cloudera or Hortonworks
- Use Databricks Unified Analytics Platform on AWS or Azure
- Use with a Hadoop PaaS solution like Amazon ElasticMapReduce or Azure HDInsight
We will look at a standalone installation but use Databricks UAP for demos.
Install Spark On Windows
Step 1: Install the Java Development Kit. I recommend getting Java Version 8. Spark is currently not compatible with JDKs after 8.
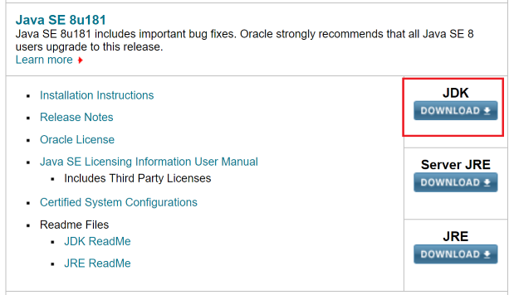
Install Spark On Windows
Step 2: Go to the Spark website and download a pre-built Spark binary.
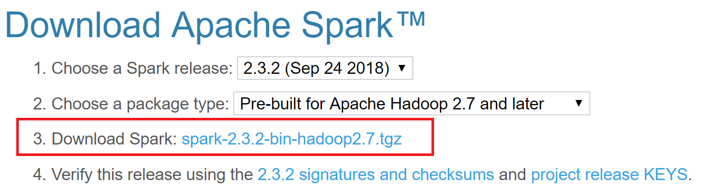
You can unzip this .tgz file using a tool like 7-Zip.
Install Spark On Windows
Step 3: Download WinUtils. This is the 64-bit version and should be 110KB. There is a 32-bit version which is approximately 43KB; it will not work with 64-bit Windows! Put it somewhere like C:\spark\bin\.
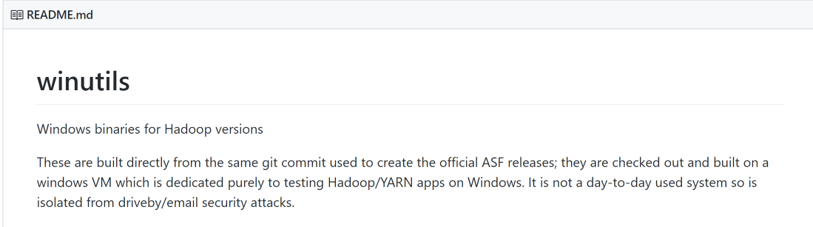
Install Spark On Windows
Step 4: Create c:\tmp\hive and open up permissions to everybody.
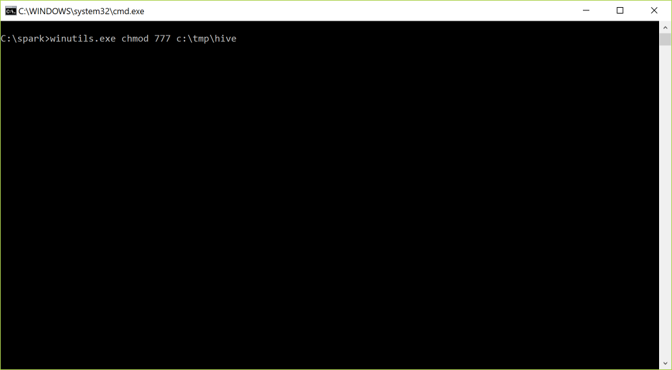
Install Spark On Windows
Step 5: Create environment variables:
SPARK_HOME >> C:\spark
HADOOP_HOME >> (where winutils is)
JAVA_HOME >> (where you installed Java)
PATH >> ;%SPARK_HOME%\bin; %JAVA_HOME%\bin;
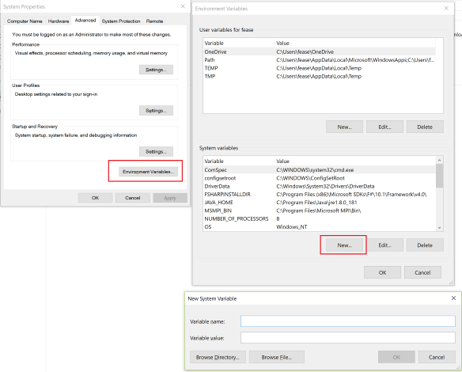
Install Spark On Windows
Step 6: Open the conf folder and create and modify log4j.properties.
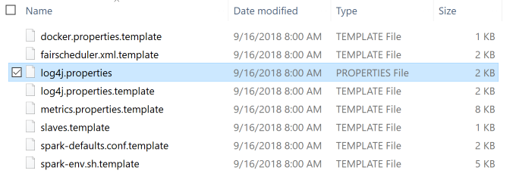

Install Spark On Windows
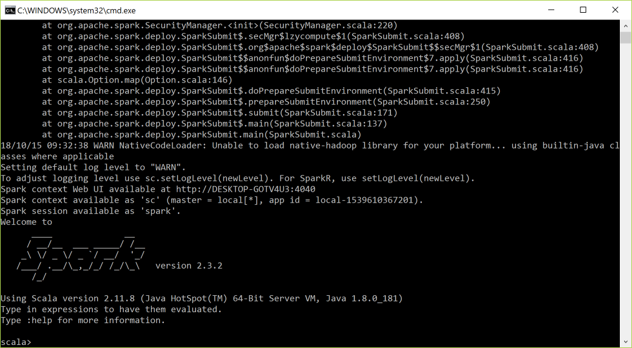
Step 7: In the bin folder, run spark-shell.cmd. Type Ctrl-D to exit the shell.
Agenda
- The Origins of Spark
- Installing Spark
- Functional Spark
- Our First Examples
- Spark SQL
- Databricks UAP
- .NET for Apache Spark
Why Scala?
Spark supports Scala, Python, and Java as primary languages and R and SQL as secondaries. We will use Scala because:
- Spark is written in Scala.
- Functionality comes out in the Scala API first.
- Scala is terser than Java but still readable.
- Scala is typically faster than Python.
- Scala is a functional programming language, which fits the data platform mindset better.
If you prefer Python or Java, that’s fine.
Functional Programming In Brief
Relevant functional programming concepts:
Set Transformations
rdd1.distinct()rdd1.union(rdd2)rdd1.intersection(rdd2)rdd1.subtract(rdd2)– Akin to theEXCEPToperator in SQLrdd1.cartesian(rdd2)– Cartesian product (CROSS JOINin SQL)
Warning: set operations can be slow in Spark depending on data sizes and whether data needs to be shuffled across nodes.
Agenda
- The Origins of Spark
- Installing Spark
- Functional Spark
- Our First Examples
- Spark SQL
- Databricks UAP
- .NET for Apache Spark
Where to Eat?
We will analyze food service inspection data for the city of Durham. We want to answer a number of questions about this data, including average scores and splits between classic restaurants and food trucks.
Demo Time
Agenda
- The Origins of Spark
- Installing Spark
- Functional Spark
- Our First Examples
- Spark SQL
- Databricks UAP
- .NET for Apache Spark
The Evolution of Spark
One of the first additions to Spark was SQL support, first with Shark and then with Spark SQL.
With Apache Spark 2.0, Spark SQL can take advantage of Datasets (strongly typed RDDs) and DataFrames (Datasets with named columns).
Spark SQL functions are accessible within the SparkSession object, created by default as “spark” in the Spark shell.
The Functional Approach
Functions provide us with SQL-like operators which we can chain together in Scala, similar to how we can use LINQ with C#. These functions include (but are not limited to) select(), distinct(), where(), join(), and groupBy().
There are also functions you might see in SQL Server like concat(), concat_ws(), min(), max(), row_number(), rank(), and dense_rank().
Queries
Queries are exactly as they sound: we can write SQL queries. Spark SQL strives to be ANSI compliant with additional functionality like sampling and user-defined aggregate functions.
Spark SQL tends to lag a bit behind Hive, which lags a bit behind the major relational players in terms of ANSI compliance. That said, Spark SQL has improved greatly since version 1.0.
Querying The MovieLens Data
GroupLens Research has made available their MovieLens data set which includes 20 million ratings of 27K movies.
We will use Apache Spark with Spark SQL to analyze this data set, letting us look at frequently rated movies, the highest (and lowest) rated movies, and common movie genres.
Demo Time
Agenda
- The Origins of Spark
- Installing Spark
- Functional Spark
- Our First Examples
- Spark SQL
- Databricks UAP
- .NET for Apache Spark
Databricks UAP
Databricks, the commercial enterprise behind Apache Spark, makes available the Databricks Unified Analytics Platform in AWS and Azure. They also have a Community Edition, available for free.
Databricks UAP
Clusters are 1 node and 15 GB RAM running on spot instances of AWS.
Data sticks around after a cluster goes away, and limited data storage is free.
Databricks UAP
Zeppelin comes with a good set of built-in, interactive plotting options.
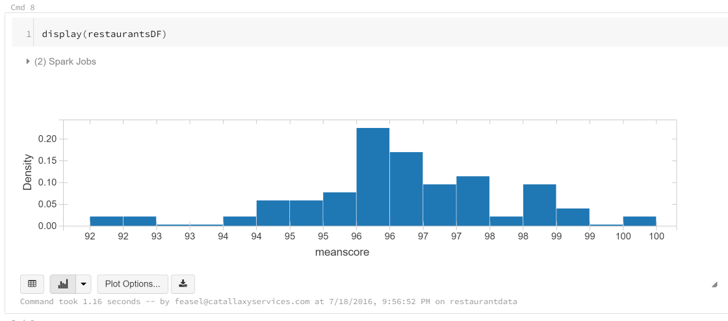
Databricks UAP
Your cluster terminates after 2 hours of inactivity. You can also terminate the cluster early.
Agenda
- The Origins of Spark
- Installing Spark
- Functional Spark
- Our First Examples
- Spark SQL
- Databricks UAP
- .NET for Apache Spark
dotnet-spark
Microsoft has official support for Spark running on .NET. They support the C# and F# languages.
With .NET code, you are limited to DataFrames and Spark SQL, so no direct access to RDDs.
Demo Time
What's Next
We've only scratched the surface of Apache Spark. From here, check out:
- MLLib, a library for machine learning algorithms built into Spark
- SparkR and sparklyr, two R libraries designed for distributed computing
- GraphX, a distributed graph database
- Spark Streaming, allowing “real-time” data processing
Wrapping Up
To learn more, go here:
https://csmore.info/on/spark
And for help, contact me:
feasel@catallaxyservices.com | @feaselkl
Catallaxy Services consulting:
https://CSmore.info/on/contact