Data Virtualization in SQL Server 2022
Kevin Feasel (@feaselkl)https://csmore.info/on/polybase
Who Am I? What Am I Doing Here?


PolyBase Revealed

- Released for SQL Server 2019
- First PolyBase-specific book ever written
- Covered PolyBase v1 (Hadoop + Azure Blob Storage) and v2 (ODBC)
Dozens of Copies Sold

Motivation
The goal of this talk is to cover Microsoft's technologies for data virtualization in SQL Server 2022, including PolyBase.
We will look at installation, configuration, and a number of practical business scenarios involving the product.
Agenda
- A Historical Review
- Installation + Configuration
- The Building Blocks
- Advanced Scenarios
What is PolyBase?
PolyBase is Microsoft's technology for covering three two use cases:
- Connecting to heterogeneous, remote data sources.
- Data virtualization: creating the appearance of local data while still having the data live remotely.
Scale-out versus scale-up and Massively Parallel Processing (MPP).
A Brief History
- Parallel Data Warehouse (2012): PolyBase introduced as a way to integrate SQL Server and Hadoop.
- SQL Server 2016: PolyBase "V1" introduced.
- Azure SQL Data Warehouse (now Azure Synapse Analytics): PolyBase used for data lake integrations.
- SQL Server 2019: PolyBase "V2" introduced. PolyBase also brought into SQL Server Big Data Clusters (RIP).
- SQL Server 2022: Some data virtualization outside PolyBase. This brings new functionality but also removes old features.
Supported Data Sources: V1
PolyBase V1 supported two external data sources:
- HDFS -- Hadoop
- WASB(S) -- Blob Storage
Supported Data Sources: V2
PolyBase V2 includes V1 data sources as well as ODBC-based integrations:
- SQL Server
- Oracle
- MongoDB / Cosmos DB
- Teradata
- Any ODBC connector -- Hive, Spark, Excel
Note that the generic ODBC connector is Windows-only.
Supported Data Sources: 2022
SQL Server 2022 eliminates V1 support.
In return, it introduces (or re-introduces):
- Amazon S3
- Azure Blob Storage (abs)
- Azure Data Lake Storage Gen2 (adls), including Delta tables
Scale: Out and Up
SQL Server is a classic "scale-up" technology: if you want more power, add more RAM/CPUs/resources to the single server.
Hadoop is a great example of an MPP system: if you want more power, add more servers; the system will coordinate processing.
PolyBase and Scale
Prior to SQL Server 2022, PolyBase offered a feature known as Scale-Out Clusters, in which you could perform PolyBase commands against multiple SQL Server instances. It looked to be the first phase in support for Massive Parallel Processing in on-premises SQL Server.
It is no longer available in SQL Server 2022. RIP.
Agenda
- What is PolyBase?
- Installation + Configuration
- The Building Blocks
- Cold Storage
- ELT
- Data Virtualization
- Tuning and Administration
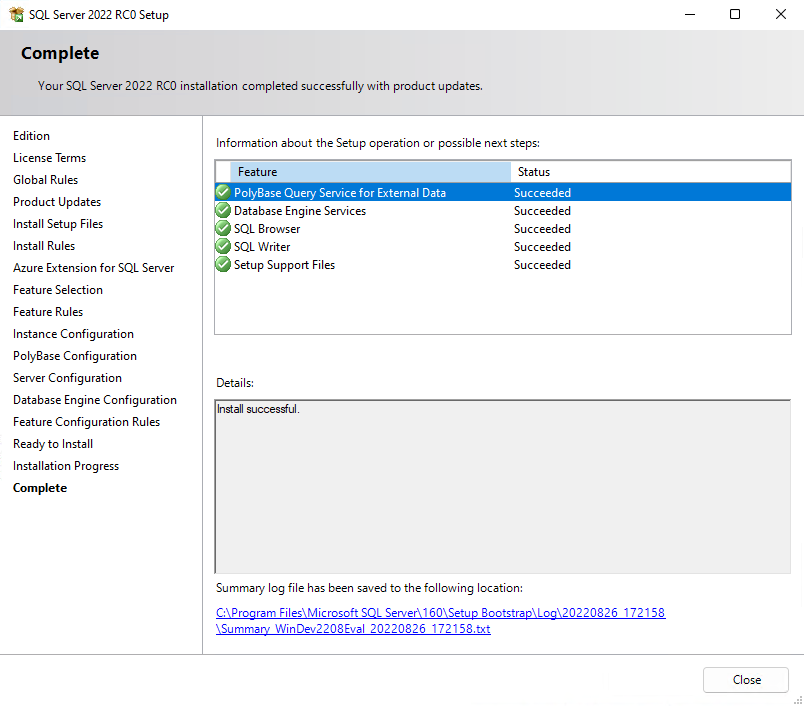
SQL Server 2022 Installation
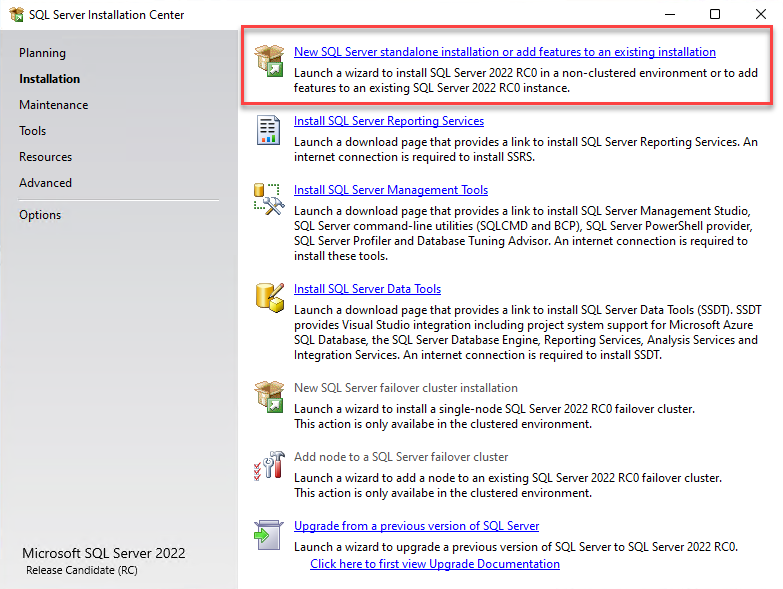
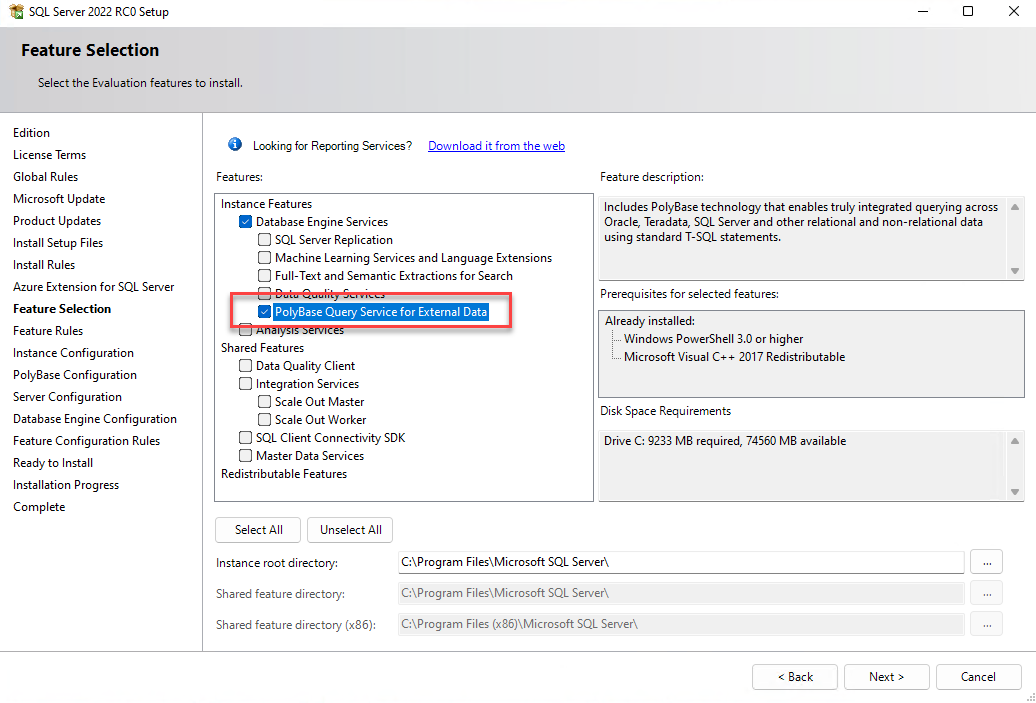
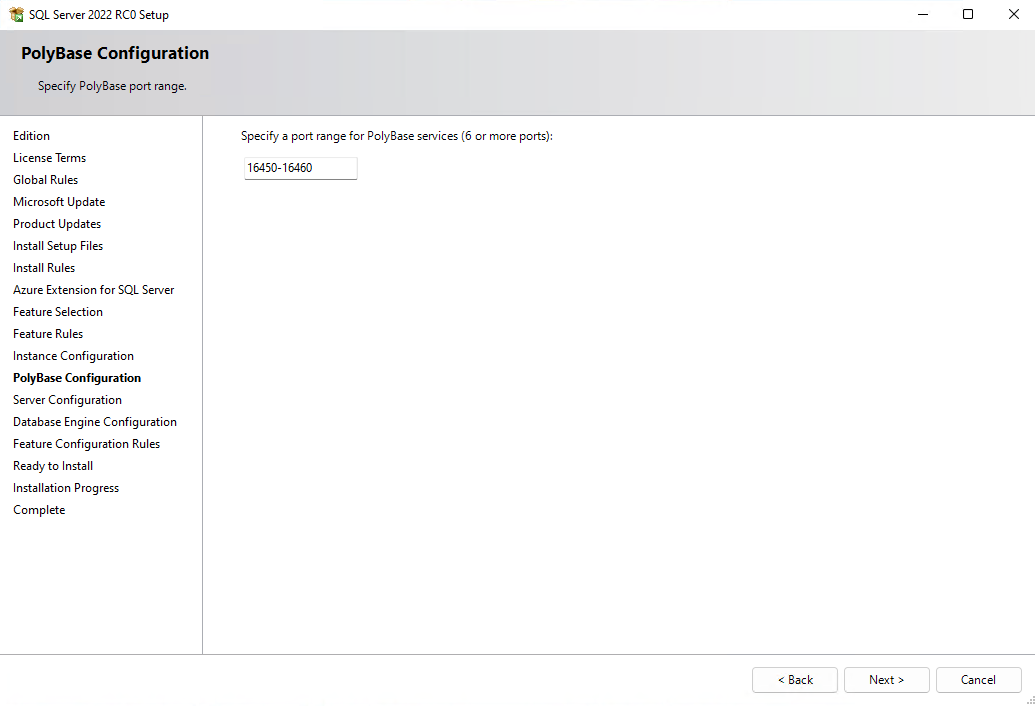
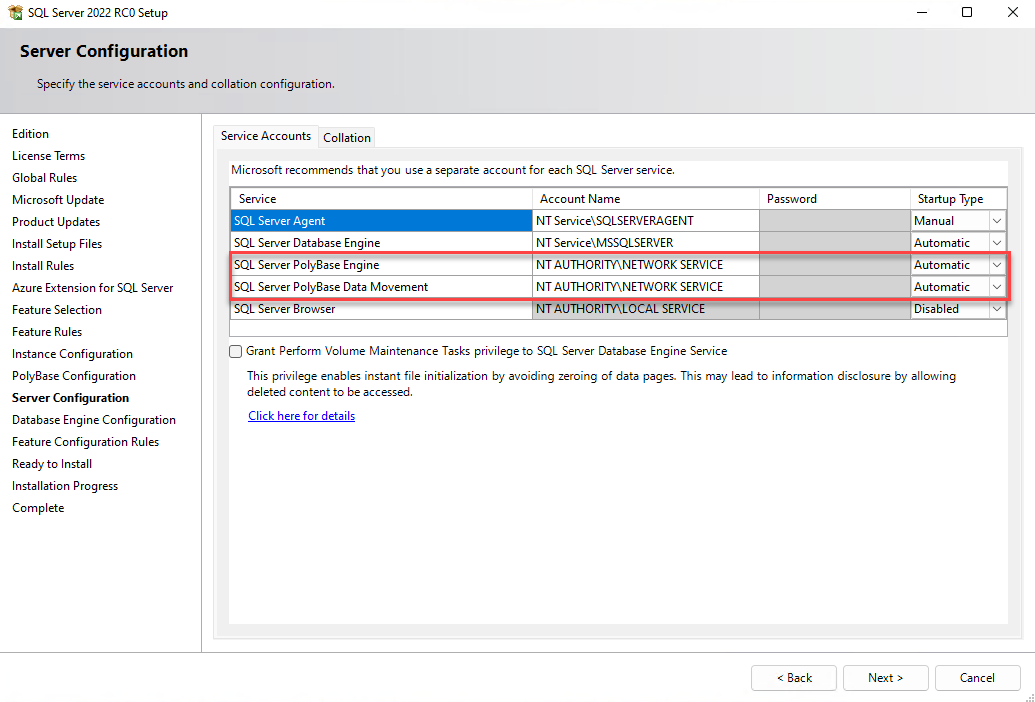
SQL Server 2019 Installation
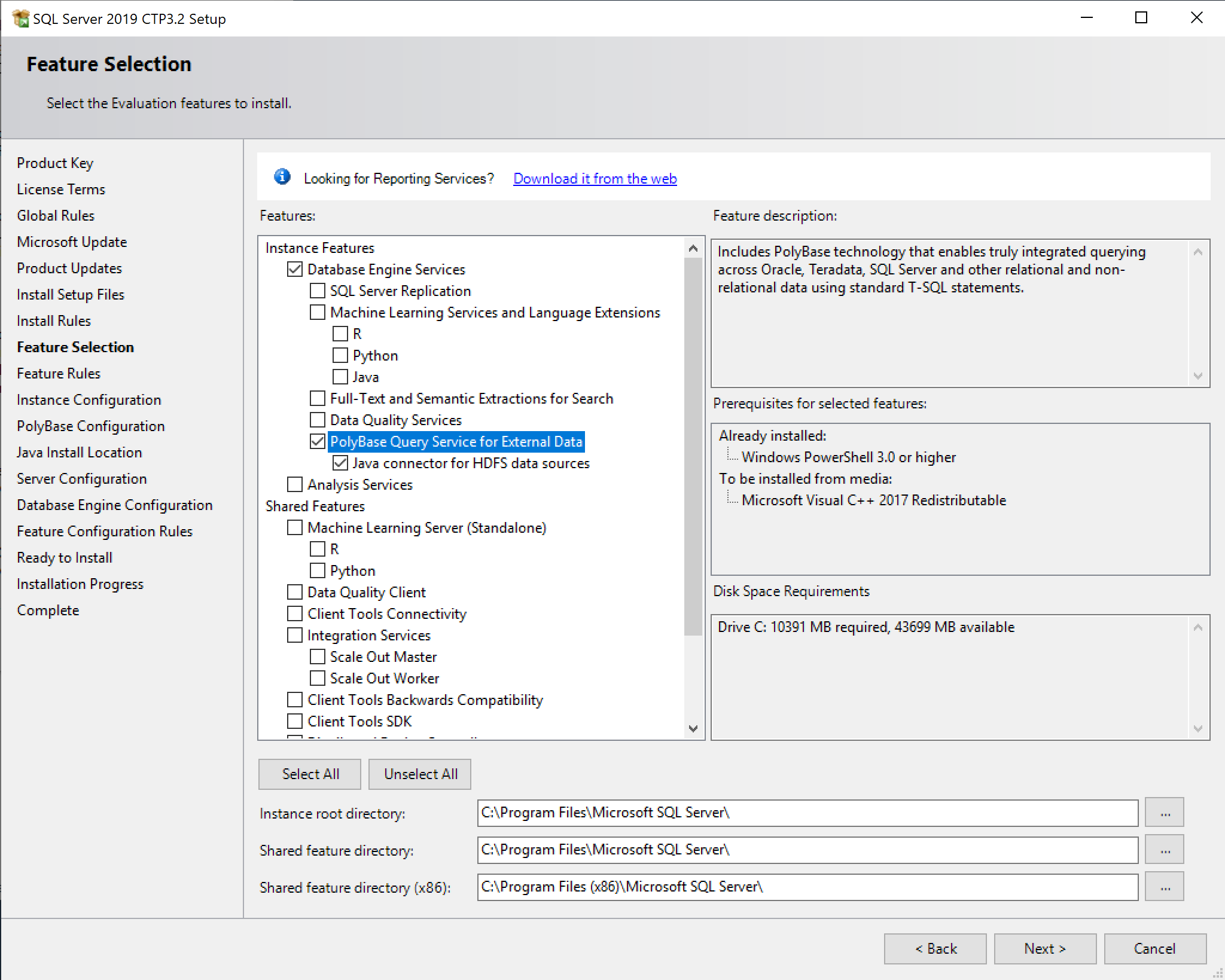
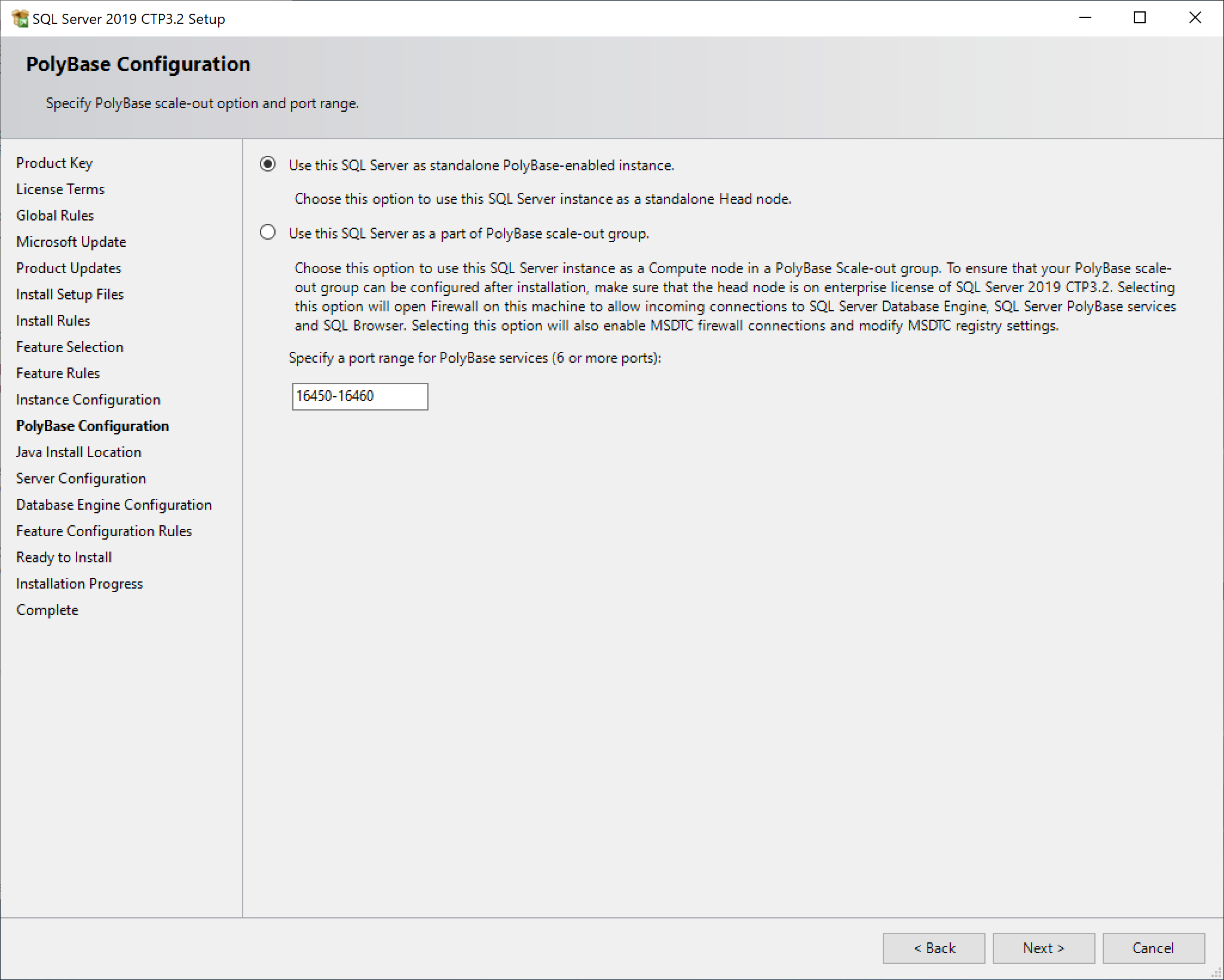
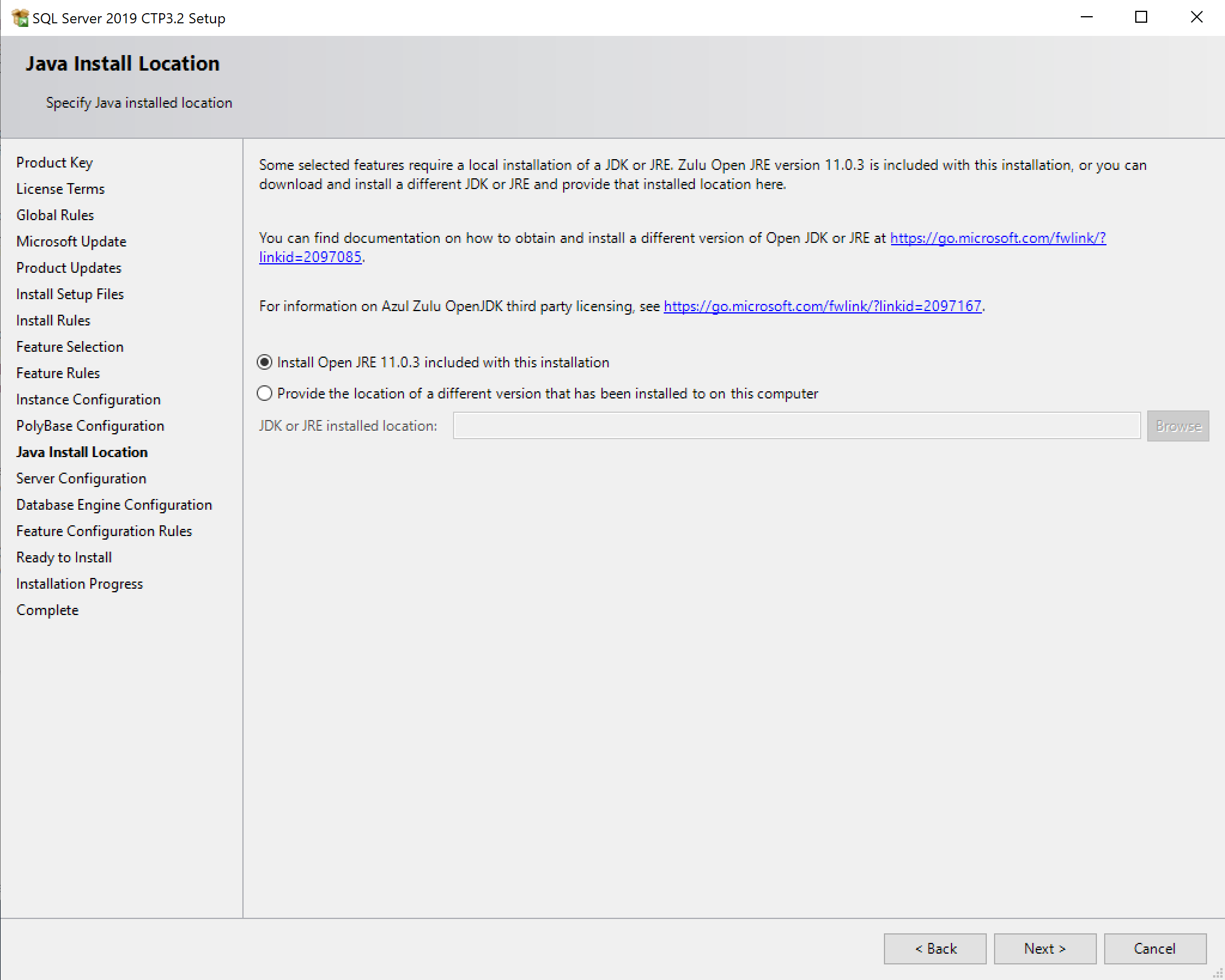
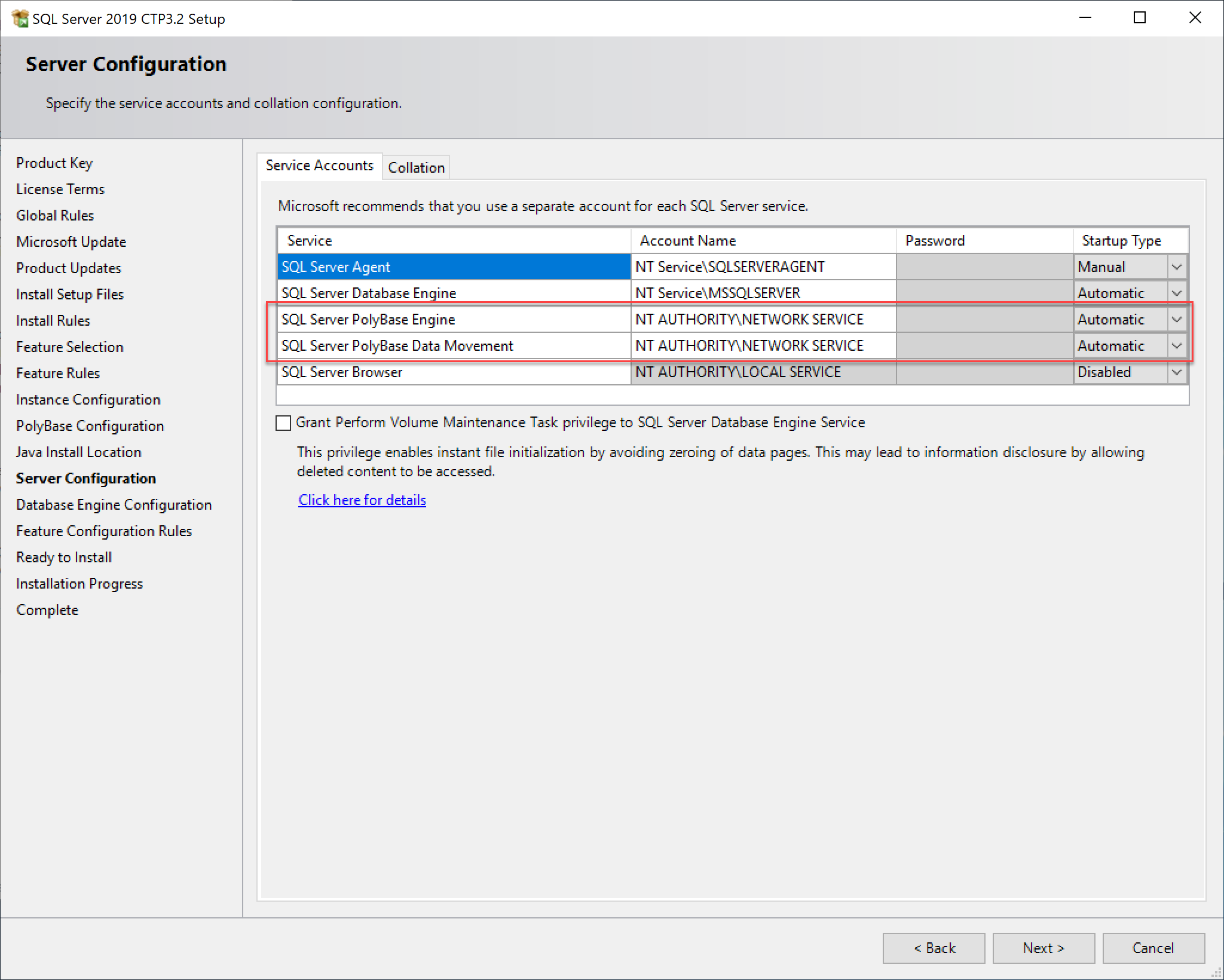
Enabling PolyBase
Driver Installation
In order to use the generic ODBC connector, you need to install an appropriate ODBC driver on the machine hosting SQL Server. Grab the right driver and follow the normal install steps.
Agenda
- A Historical Review
- Installation + Configuration
- The Building Blocks
- Advanced Scenarios
External Objects
Three sorts of external objects exist.
- External Data Source
- External File Format
- External Table
External Data Source
An external data source tells SQL Server where it can find remote data.
That data does not migrate to SQL Server! It lives on the external data source.
Azure Blob Storage
SQL Server
Spark
External File Format
An external file format tells SQL Server what type of file you intend to use. SQL Server supports delimited files (e.g., comma or tab separated), ORC, and Parquet formats.
This is not required for V2 data sources, as they do not read from files. It is required for Blob Storage/Data Lake Storage and S3.
CSV (with Header)
Optimized Row Columnar (ORC)
External Table
An external table tells SQL Server the structure of your external resource. SQL Server requires structured data and will reject records which do not fit the data types and sizes you set.
Rejection and You
Going from unstructured to structured data is a risk: conversions may fail. When that happens, the PolyBase engine rejects that row. After we meet a rejection threshold, PolyBase fails the query.
Rejection and You
The three parameters we control are:
REJECT_TYPE : { VALUE, PERCENTAGE }
REJECT_VALUE
REJECT_SAMPLE_VALUE = Number of rows to pull in before recalculating rejection percentage.
Demo Time
Agenda
- A Historical Review
- Installation + Configuration
- The Building Blocks
- Advanced Scenarios
Cold Storage
Assumptions:
- You have one or more giant tables in SQL Server.
- Users only query a small, pre-known fraction of that data (e.g., last year or last 2 years).
- Occasionally someone needs this under-utilized data.
- When users do need the under-utilized data, they can afford to wait a while.
Cold Storage
Technique: write old data to Azure Blob Storage / Hadoop and use partitioned views to join back together.
Benefits:
- Blob Storage and HDFS tend to be much cheaper than SQL Server disks
- Less data >> faster queries on SQL server
- Partitioned views mean no code changes are necessary and queries automatically benefit
ELT
Assumptions:
- You need the same data in multiple databases, such as OLTP + warehouse
- You have processes in place (e.g., SSIS packages) to Extract, Transform, and Load this data
- You have a large amount of data
ELT
Technique: instead of Extract-Transform-Load, use PolyBase and the Extract-Load-Transform (ELT) pattern to land and transform data.
Benefits:
- ELT is typically less memory-intensive than ETL
- ELT scales to larger data sizes than ETL
- ELT with PolyBase lets you stick with T-SQL instead of T-SQL + SSIS / Biml + C#
Data Virtualization
Assumptions:
- You have data in several, different source systems
- These source systems use several technologies, such as SQL Server, Oracle, Spark, Cosmos DB, etc.
- You would like to query these source systems with T-SQL and integrate them together in your queries
- Performance is not a key consideration
Data Virtualization
Technique: use PolyBase external data sources and external tables to create SQL Server representations of data sets.
Benefits:
- One language to query them all
- Users do not need to know where the data really lives
- All filtering, reshaping, and data logic works as T-SQL regardless of the data's origin
Demo Time
Wrapping Up
SQL Server 2022 offers an update to data virtualization, retaining ODBC-based PolyBase and adding an API-based virtualization process.
Data virtualization in SQL Server has a number of useful business cases. It won't give you the greatest performance, but if you want a unified SQL interface and performance is not a top consideration, it does the job.
Wrapping Up
To learn more, go here:
https://csmore.info/on/polybase
And for help, contact me:
feasel@catallaxyservices.com | @feaselkl
Catallaxy Services consulting:
https://CSmore.info/on/contact