Where We're Going, We Don't Need Servers
The Serverless SQL Pool in Azure Synapse Analytics
Kevin Feasel (@feaselkl)http://CSmore.info/on/serverless
Who Am I? What Am I Doing Here?



Motivation
My goals in this talk:
- Understand what the Azure Synapse Analytics serverless SQL pool is.
- Load data into the serverless SQL pool.
- Query data in the serverless SQL pool.
- Get a feeling for how much all of this will cost.
Agenda
- An Overview
- Creating a Serverless SQL Pool
- Querying Data
- Spelunking and Data Analysis
- Building a Logical Data Warehouse
- Securing Data
- Financing the Endeavor
Azure Synapse Analytics
Azure Synapse Analytics is Microsoft's platform for modern data warehousing. It is made up of four components:
- Dedicated SQL pools
- Spark pools
- Serverless SQL pool
- Data explorer pools (preview)
Dedicated SQL pools
Azure Synapse Analytics dedicated SQL pools, nee Azure SQL Data Warehouse, offer up a Massive Parallel Processing approach to data warehousing and work best in classic data warehousing scenarios:
- You are using the Kimball model of facts and dimensions.
- Your total data size is at least 1 TB.
- Your major fact tables have at least 1 billion rows of date and numeric data.
- Your major dimension tables are relatively small but wide.
- Users typically work off of a set number of queries.
Spark pools
Azure Synapse Analytics Spark pools allow you to spin up Apache Spark clusters. Key use cases for these Spark clusters include:
- Complicated data transformation projects, such as working with regular expressions.
- Distributed machine learning tasks not suited for Azure Machine Learning.
- Migrating work from on-premises Apache spark clusters or HDInsight clusters.
Serverless vs Dedicated SQL pools
Azure Synapse Analytics serverless SQL pools are a bit different from dedicated SQL pools in the following ways:
- Serverless SQL pools do not store data. They read files directly from your data lake and expose them as SQL tables.
- Serverless SQL pools require no infrastructure or resource reservation and have no up-front costs.
- The pricing model for serverless SQL pools is based on data utilization: approximately $5 per terabyte of data processed.
Serverless SQL pool
Key use cases for the Azure Synapse Analytics serverless SQL pool include:
- Data "spelunking:" investigatory work on data in the data lake.
- Logical data warehousing: virtualization of data stored in Azure Data Lake Storage and Cosmos DB.
- Simple data transformations and cleanup as part of data curation.
- Reviewing data processed in Spark pools.
Data Explorer pools
Data Explorer pools allow you to perform real-time analysis on large volumes of data. The initial use case of this was to process log data, but using the Kusto Query Language (KQL), we can also perform detailed time series analysis, whether real-time or off of already-stored data.
Agenda
- An Overview
- Creating a Serverless SQL Pool
- Querying Data
- Spelunking and Data Analysis
- Building a Logical Data Warehouse
- Securing Data
- Financing the Endeavor
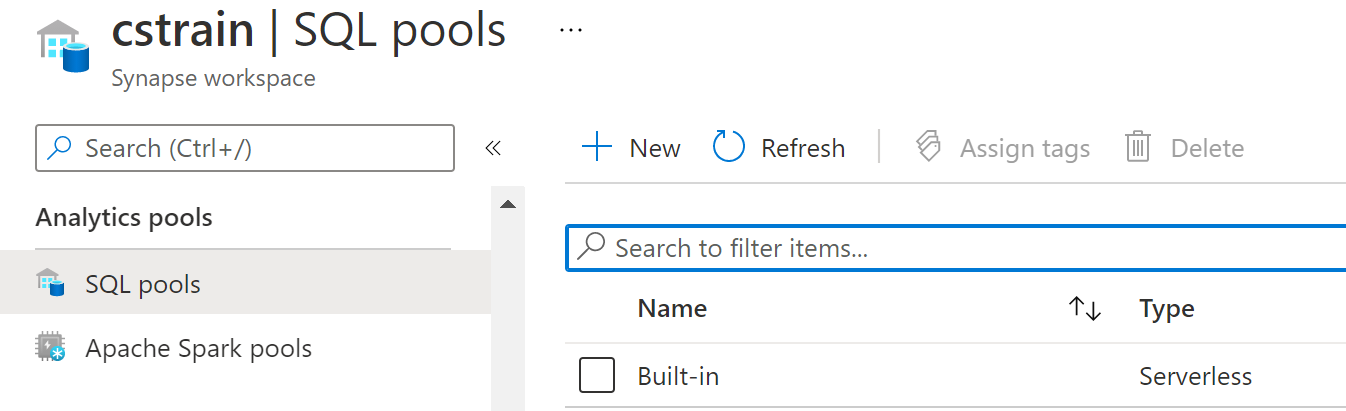
The Built-In Pool
Each Azure Synapse Analytics workspace comes with a built-in serverless pool.
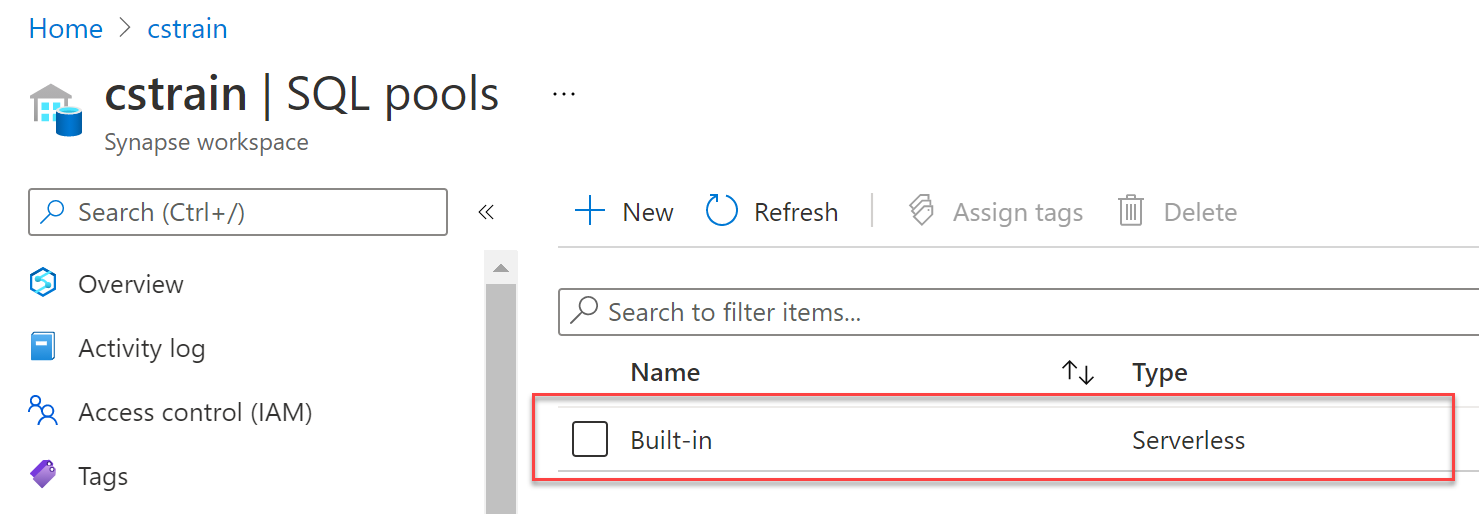
Creating a New Serverless Pool
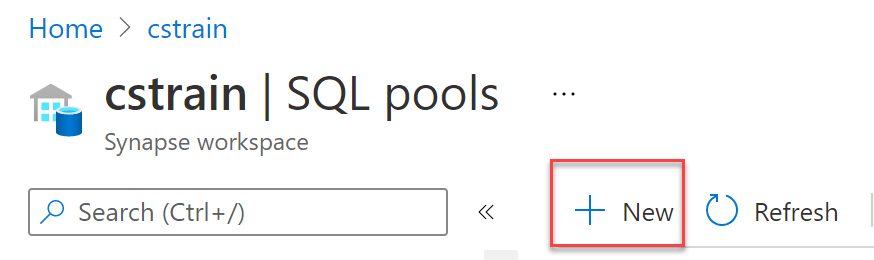
You cannot create additional serverless SQL pools. Although there is an option to create a new SQL pool, it only allows you to create dedicated SQL pools.
Destroying or Deleting a Serverless SQL Pool
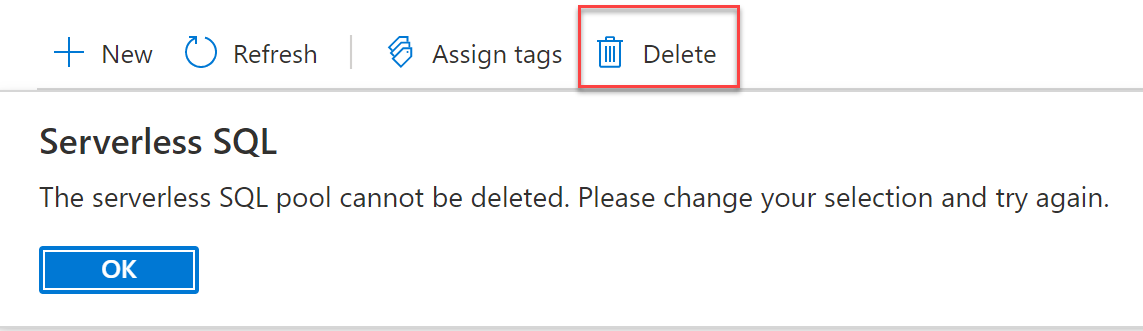
Similarly, you cannot delete a serverless SQL pool. But if you don't use the serverless SQL pool to retrieve data, you never get charged for it.
Agenda
- An Overview
- Creating a Serverless SQL Pool
- Querying Data
- Spelunking and Data Analysis
- Building a Logical Data Warehouse
- Securing Data
- Financing the Endeavor
Our Scenario
We work for an agency known as Martian Agricultural Data Collection and Ownership (MADCOW).
Our job is to collect sensor data from agricultural plots in several Martian cities in order better to understand which plots of land are best suited for specific crops.
Our system has collected a significant amount of IoT sensor data and management would like us to build a rapid access system for reviewing this data. We have chosen the Azure Synapse Analytics serverless SQL pool for the job.
What Language Do We Use?
The serverless SQL pool allows you to write T-SQL queries. But the product does not support the entire T-SQL namespace.
One major reason for this is that serverless SQL pools are (almost entirely) read-only.
How Do We Load Data if Serverless SQL Pools Are Read-Only?
The easiest way to access data from a serverless SQL pool is to load it from Azure Data Lake Storage.
Every Azure Synapse Analytics workspace has an associated data lake storage account.
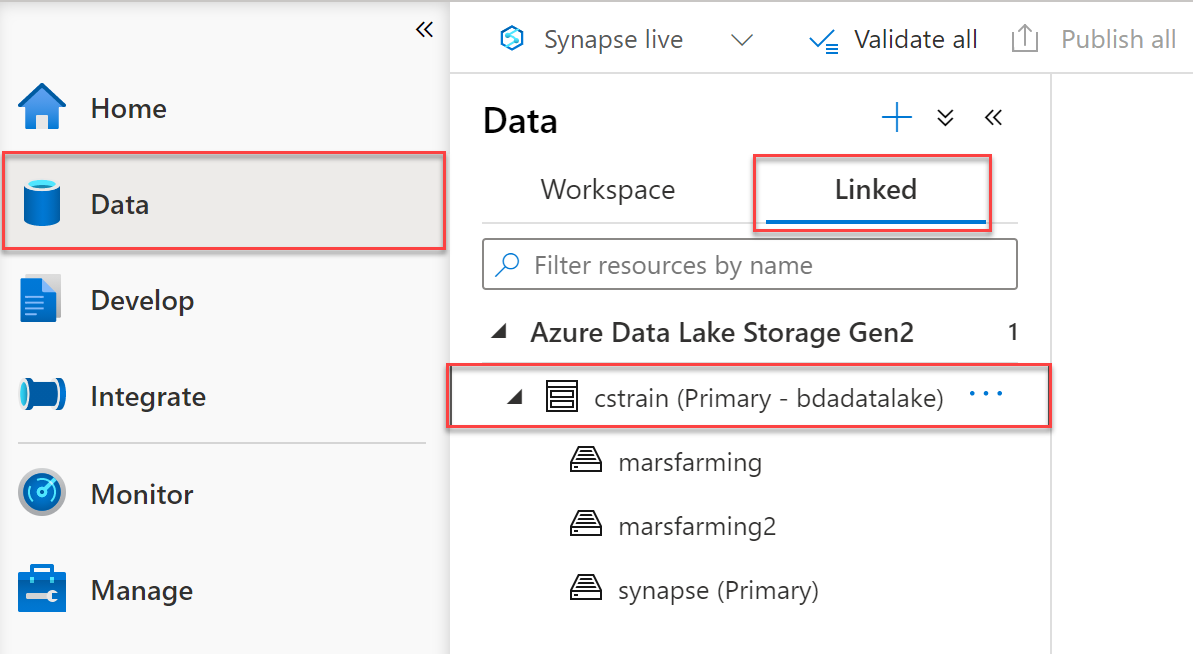
Bulking Up the SQL Pool with OPENROWSET
The OPENROWSET command allows you to read data from a file or folder.
OPENROWSET: Supported File Types
The OPENROWSET command supports the following data types:
- CSV (or other delimited file)
- Parquet
- JSON
- Delta Lake
Delta Lake
Azure Synapse Analytics has some support for the Linux Foundation's Delta Lake (gifted by Databricks). Delta Lake has several beneficial features:
- ACID-like serializable transaction support
- "Time travel:" ability to view the history of a record, including reverting rows if needed
- Schema enforcement via use of the Parquet file format
- Insert, update, delete, and merge capabilities (including via Spark SQL)
Demo Time
External Tables with PolyBase
Azure Synapse Analytics extends a Microsoft technology called PolyBase, which allows you to virtualize data from a number of different data platform technologies. The most important one for our use case is, again, Azure Data Lake Storage Gen2.
For more on PolyBase itself, go to https://csmore.info/on/polybase.
External Objects
Three sorts of external objects exist.
- External Data Source
- External File Format
- External Table
External Data Source
An external data source tells the serverless SQL pool where it can find remote data.
That data does not migrate to the serverless SQL pool! It lives on the external data source.
External File Format
An external file format tells the serverless SQL pool what type of file you intend to use from our data lake. We can use delimited files (e.g., comma or tab separated), ORC, and Parquet formats.
External Table
An external table tells your serverless SQL pool the structure of your external resource. The serverless SQL pool requires structured data and will reject records which do not fit the data types and sizes you set.
Combined Arms
You can combine the OPENROWSET approach with PolyBase's CREATE EXTERNAL TABLE AS (CETAS) in order to shape external tables before creation.
Demo Time
Agenda
- An Overview
- Creating a Serverless SQL Pool
- Querying Data
- Spelunking and Data Analysis
- Building a Logical Data Warehouse
- Securing Data
- Financing the Endeavor
Spelunking
The serverless SQL pool is great for ad hoc data exploration. They allow you to query arbitrary files or folders within a data lake, shape that data using T-SQL, and display or export the data in several ways.
Filepath Searches
OPENROWSET queries may load data from a single file.
Filepath Searches
Using wildcard characters like "*" we can change that to include a variety of files.
Filepath Searches
Going further, we can use FILEPATH() and FILENAME() to get details on a file.
Filepath Searches
The end result is a listing of numbers of rows per file.
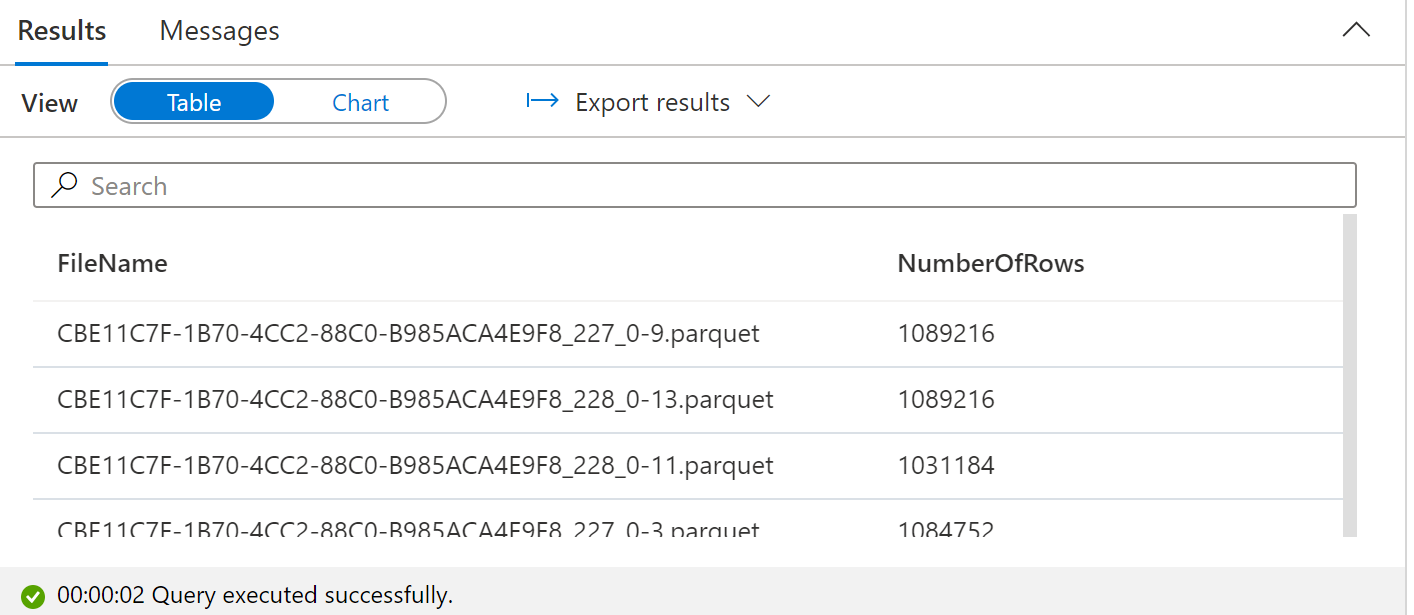
Filepath Searches
But we can include more than one wildcard and can even reference them in the query itself using FILEPATH().
Filepath Searches
This lets us analyze data even in the case in which we don't specify year or month in the files themselves--just by virtue of being in the right folder, we can get relevant context!
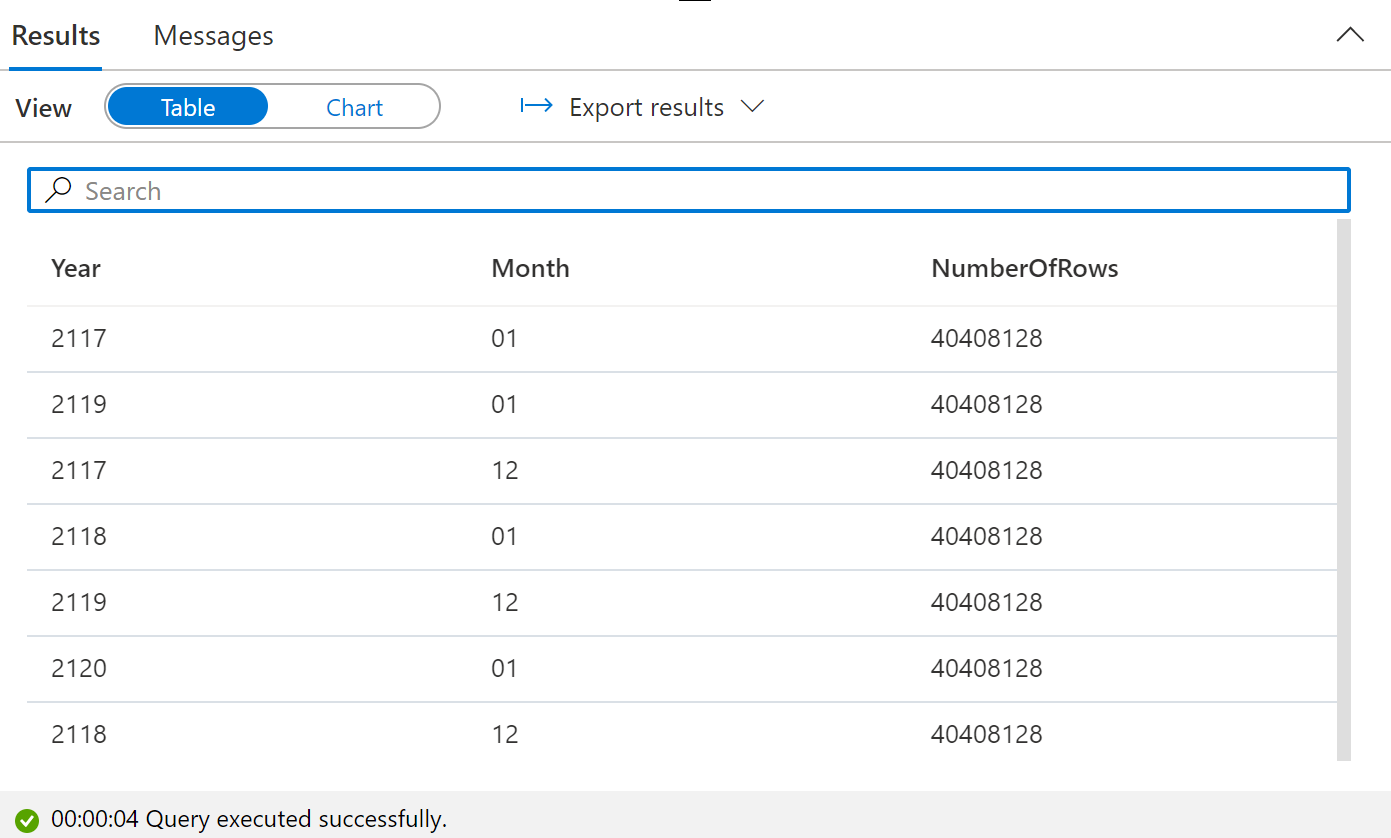
Filepath Searches
We can even use these in the WHERE clause to filter:
Filepath Searches
In this case, we filter to include only files which start with the letter "C" and ignore all other files.
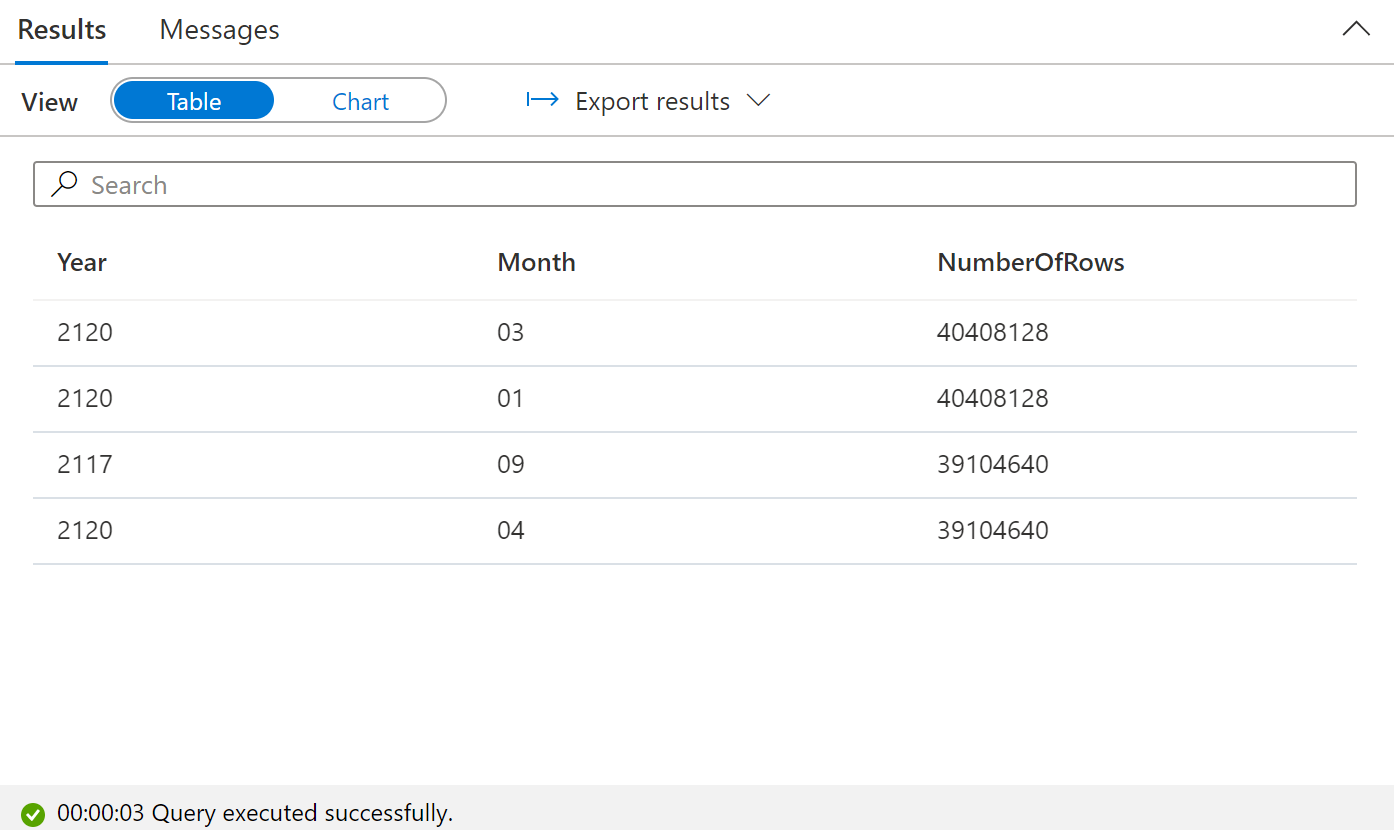
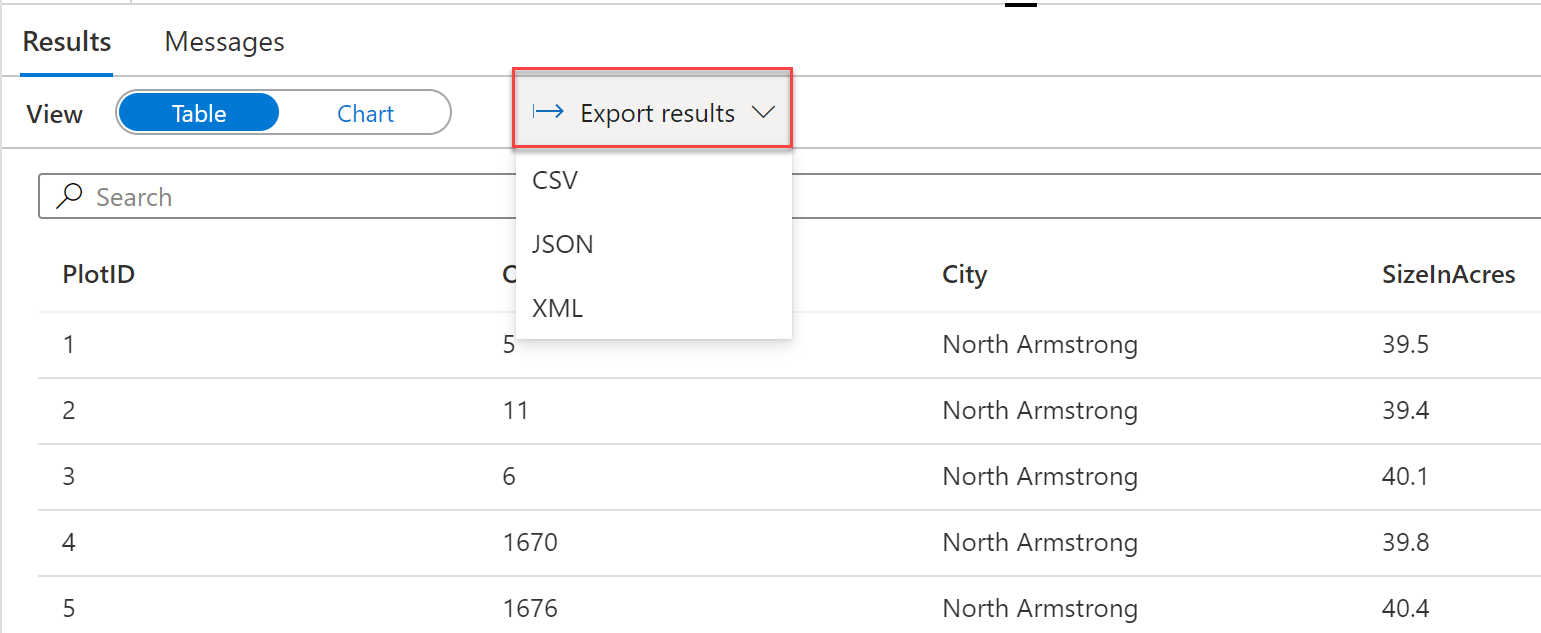
Data Exportation
Azure Synapse Analytics queries be exported directly to CSV, JSON, or XML.
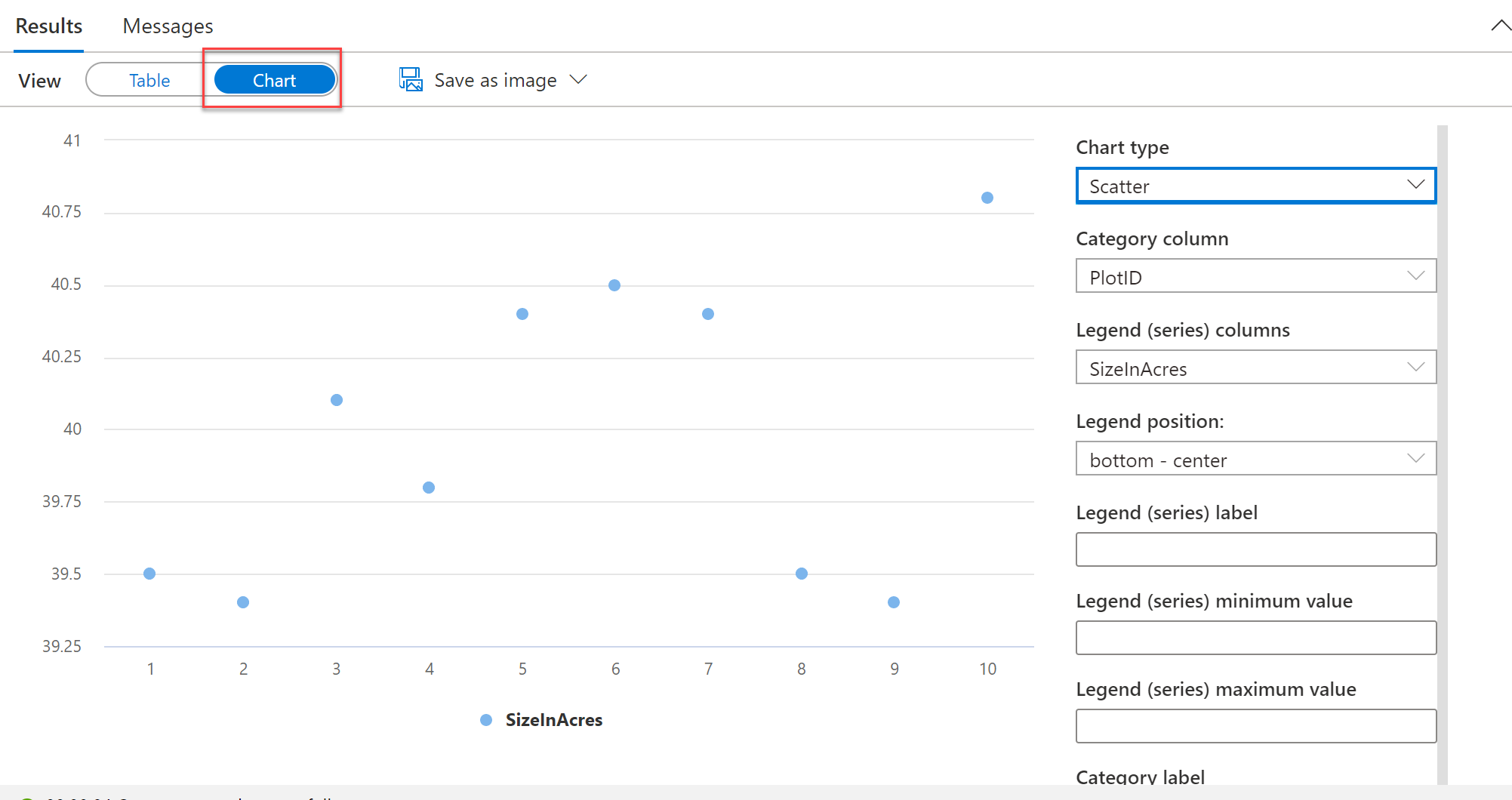
Data Visualization
Azure Synapse Analytics includes a charting library similar to that in Azure Data Studio.
Demo Time
Agenda
- An Overview
- Creating a Serverless SQL Pool
- Querying Data
- Spelunking and Data Analysis
- Building a Logical Data Warehouse
- Securing Data
- Financing the Endeavor
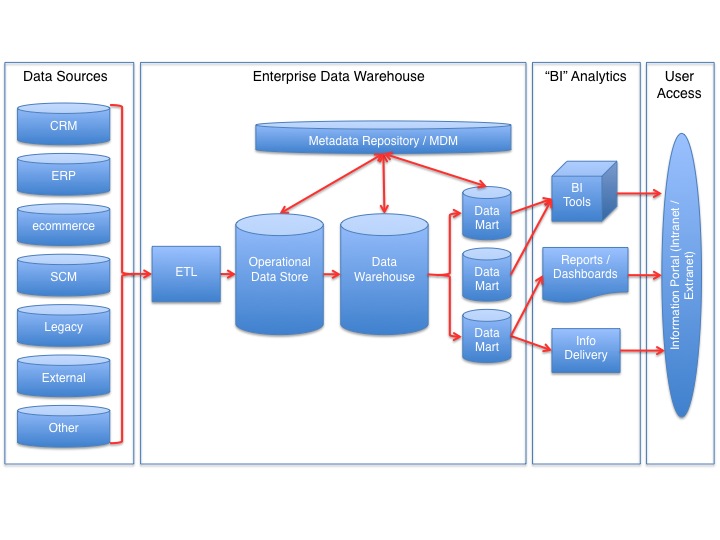
The Logical Data Warehouse
Historically, we have built physical data warehouses as a way of storing data for solving known business problems. We can also create logical (virtual) data warehouses and query from separate systems when that makes sense.
The Data Lakehouse
Databricks has coined the term Lakehouse to represent the combination of data warehouse and data lake in one managed area.
The Data Lakehouse
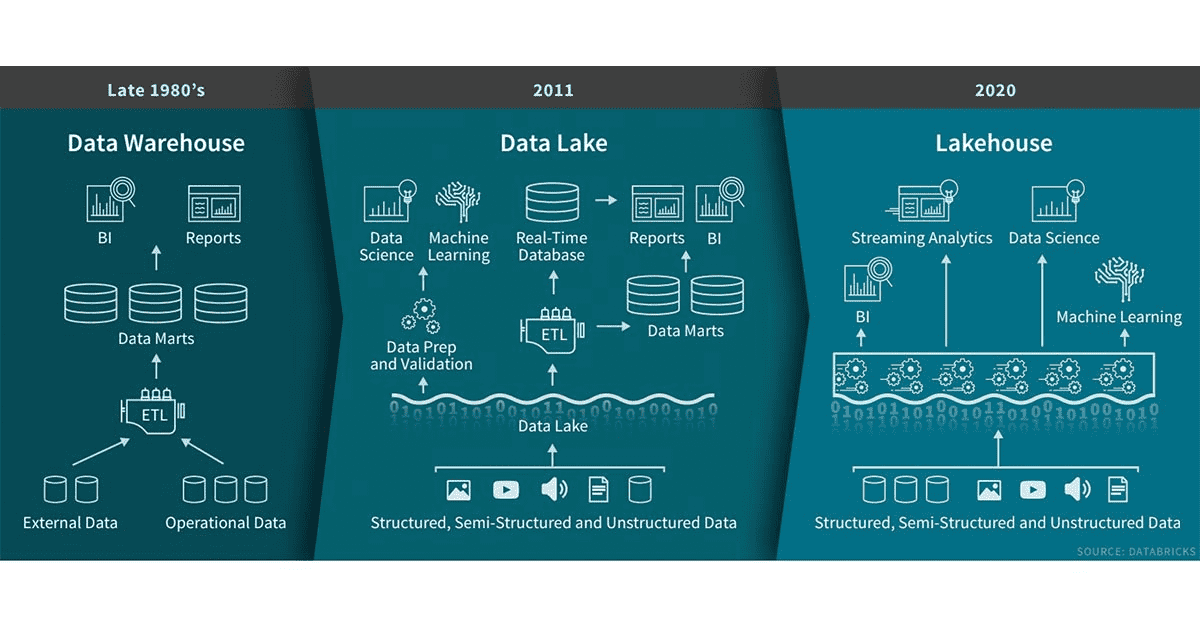
The Logical Data Warehouse
A logical data warehouse in a serverless SQL pool isn't exactly the same thing as the Data Lakehouse, but there are some similarities in approach.
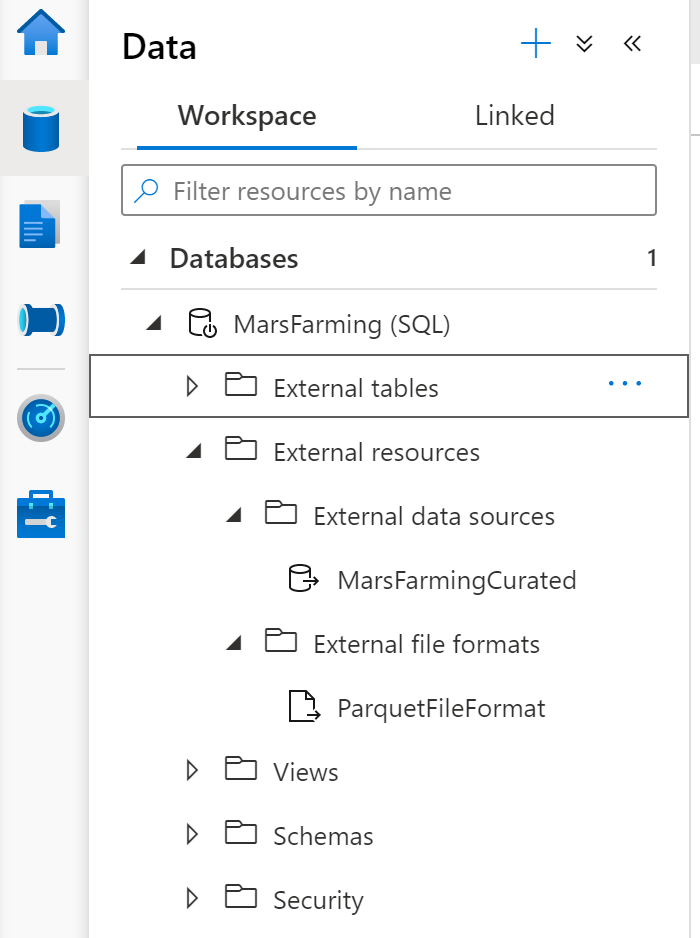
Demo Time
Agenda
- An Overview
- Creating a Serverless SQL Pool
- Querying Data
- Spelunking and Data Analysis
- Building a Logical Data Warehouse
- Securing Data
- Financing the Endeavor
Security Options
The serverless SQL pool doesn't have the same breadth of security options and roles as on-premises SQL Server instances, but there are still ways to control access to data.
- Controlling the underlying data
- Role-based security
- Access to objects or schemas
- Administer Database Bulk Operations
- Granting Control
- Row-level security
Controlling the Underlying Data
The easiest way to grant access to files or folders in a Data Lake is to generate a SAS token.
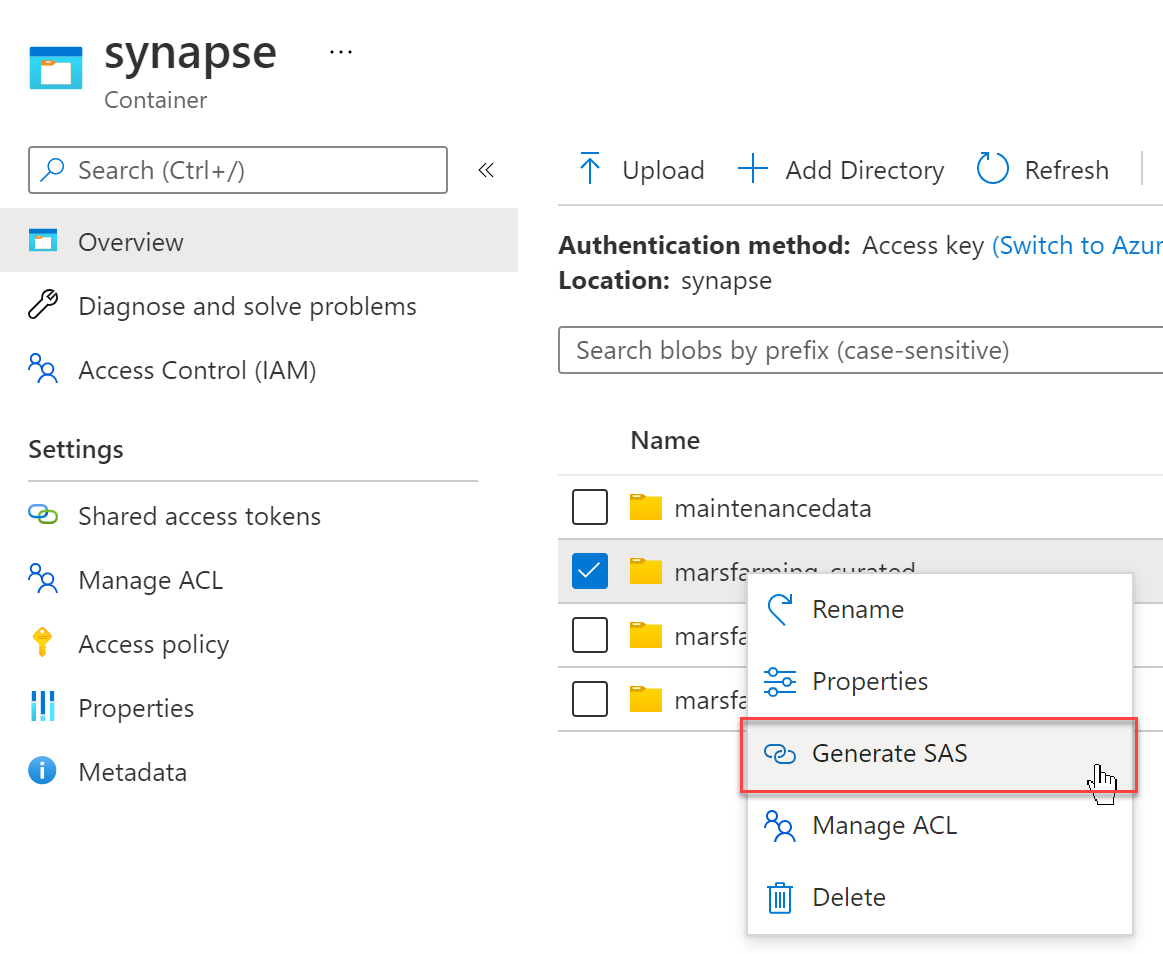
SAS tokens can expire after a set amount of time and have specific rights. For our needs, we want at least Read and List permissions.
Controlling the Underlying Data
You may have several tokens available to a serverless SQL pool as database scoped credentials.
Role-Based Security
The serverless SQL pool allows you to create distinct roles and assign users to them, just as you can on-premises.
Access to Objects or Schemas
You may GRANT permissions to specific objects or schemas. This is a good option for regular users who just need to query tables in a logical data warehouse.
Administer Bulk Database Operations
In order to allow users to view data using OPENROWSET, you will need to grant rights for bulk database operations, as OPENROWSET is a bulk operation in SQL Server.
Granting Control
Just as on-premises, the CONTROL permission is very strong. It allows a user to set up permissions, create (or destroy) external tables or views, and query data via OPENROWSET. Save this for administrators or power users.
Row-Level Security
We can also control access to specific rows in data based on role. Unlike SQL Server on-premises, there is no native row-level security. We can, however, create it via views and (optional) table-valued functions.
Suppose we have specific analysts by city.
Row-Level Security
Row-Level Security
Another option is to wrap the security in an inline table-valued function.
Row-Level Security
We can then use CROSS APPLY to apply the security rules.
Agenda
- An Overview
- Creating a Serverless SQL Pool
- Querying Data
- Spelunking and Data Analysis
- Building a Logical Data Warehouse
- Securing Data
- Financing the Endeavor
How Much Does this Cost?
The different components of Azure Synapse Analytics are priced differently. Although dedicated SQL pools and Spark pools are priced by server utilization, the serverless SQL pool is priced by data processed, at a rate of approximately $5 per terabyte processed.
What Does it Mean to Process Data?
Data processing includes data read, metadata read, data in intermediate storage during queries (e.g., spools or temp tables), data written to storage via CETAS, and data transferred between nodes or out to the end user.
Each query has a minimum of 10 MB of data processed. As such, try to avoid an enormous number of small queries off of tiny files, as those will add up quickly.
How Do We Save Money?
We know that scanning the minimum amount of data necessary is a key for maximizing performance. It's also our key for saving money here. The serverless SQL pool offers a few techniques for doing this:
- Using the right file format
- Returning smaller result sets
- Filename and file path filtering
- Pre-calculating frequently used aggregates
Use the Right Format
Typically, Parquet format will be superior to CSVs for handling data in a data lake. This is for a few reasons:
- Parquet compresses data to a smaller size than CSV
- Parquet includes column metadata, making querying easier
- With Parquet, you only read in the columns you need--it's a columnar format
Return Smaller Result Sets
The downside to compression is that data is returned back in result sets uncompressed.
If your query reads 1 TB of Parquet data and the compression ratio is 5:1 and your query returns back the entirety of this data, you will be charged for 1 TB of compressed data read from disk plus 5 TB of data transferred out, or 6 TB in total.
By contrast, aggregating the data will result in much smaller result sets and lower prices.
Perform Filename and File Path Filtering
Using filters on FILENAME() and FILEPATH() can allow you to narrow down which files to read and what data to return.
Furthermore, when using OPENROWSET for ad hoc queries, narrow down to the smallest number of folders or files needed to get the job done.
Pre-Calculate Frequently Used Aggregates
If you have frequently used aggregates, it may make sense to calculate them once and store the results in files for later use. In that case, you will incur a one-time charge to calculate the aggregates but then a small charge (down to 10 MB of data processed) per access.
Pre-Processing Data
Sometimes, in order to improve performance, the serverless SQL pool will process more data than absolutely necessary. For example, the CSV reader pulls in data in chunks, and although you only asked for 5 rows, the chunk might contain 50 or 100. The net effects of this are typically small, but can add up with a large number of queries.
To reduce this, store data in Parquet format and write queries which intend to read from an entire file rather than part of the file. This might include reshaping files in your data lake.
Calculating Data Processed
Each serverless SQL pool has an associated DMV which calculates the amount of data processed: sys.dm_external_data_processed.
Demo Time
Wrapping Up
This has been a look at the serverless SQL pool in Azure Synapse Analytics. Although it is in the SQL Server family, it's closer to second cousins with on-premises SQL Server rather than a twin.
Wrapping Up
To learn more, go here:
https://CSmore.info/on/serverless
And for help, contact me:
feasel@catallaxyservices.com | @feaselkl
Catallaxy Services consulting:
https://CSmore.info/on/contact